9 Classic Web Scraper
This documentation shows you how to setup a classic web scraper. We recommend you use this method if there is no rss feed available This example here is really just a guideline for web scrapers. While every webpage is built differently there are some ground structures every webpage has. Hence, we can show how to use this structure to obtain data from webpages.
If this method does not work there is still the possibility that there might be some workaround for your problem, which is missing in this documentation. Otherwise you could also try to scrape the webpage using Selenium. But try to use the method described here as Selenium is a bit more complex to work with on a daily basis.
Again, please consider: Just because you can do web scraping doesn’t mean that you always should. There may be terms and conditions that explicitly forbid you to do so. We cannot stop you from violating this but be aware that there are methods to prevent you from doing so. Secondly be kind to the webhosts server and try to minimize the load you put on it. A web scraper without timeouts will put quite a load on the server. A good guideline is to build your web scraper which only clicks or load one element per second.
9.1 Preprocessing
To make working web scrapers you normally need a few libraries. These are basically packages like RCurl, httr, XML and rvest, which contain the necessary tools to access webpages and copy data from them. Other packages are used to parse and save the data in your desired format. With these packages installed you should have no problem scraping data from pages many pages. Some other useful packages are tabulizer which is great if the data you want is only available through pdf with tables and pdftools which is great to read in text from pdf files.
9.2 Libraries
Load the libraries needed to execute the code.
9.3 Data Collection
9.3.1 Step 1)
First you have to open a browser (best use Firefox or Chrome) and navigate to the website. There you have to look were the data is you need is located.
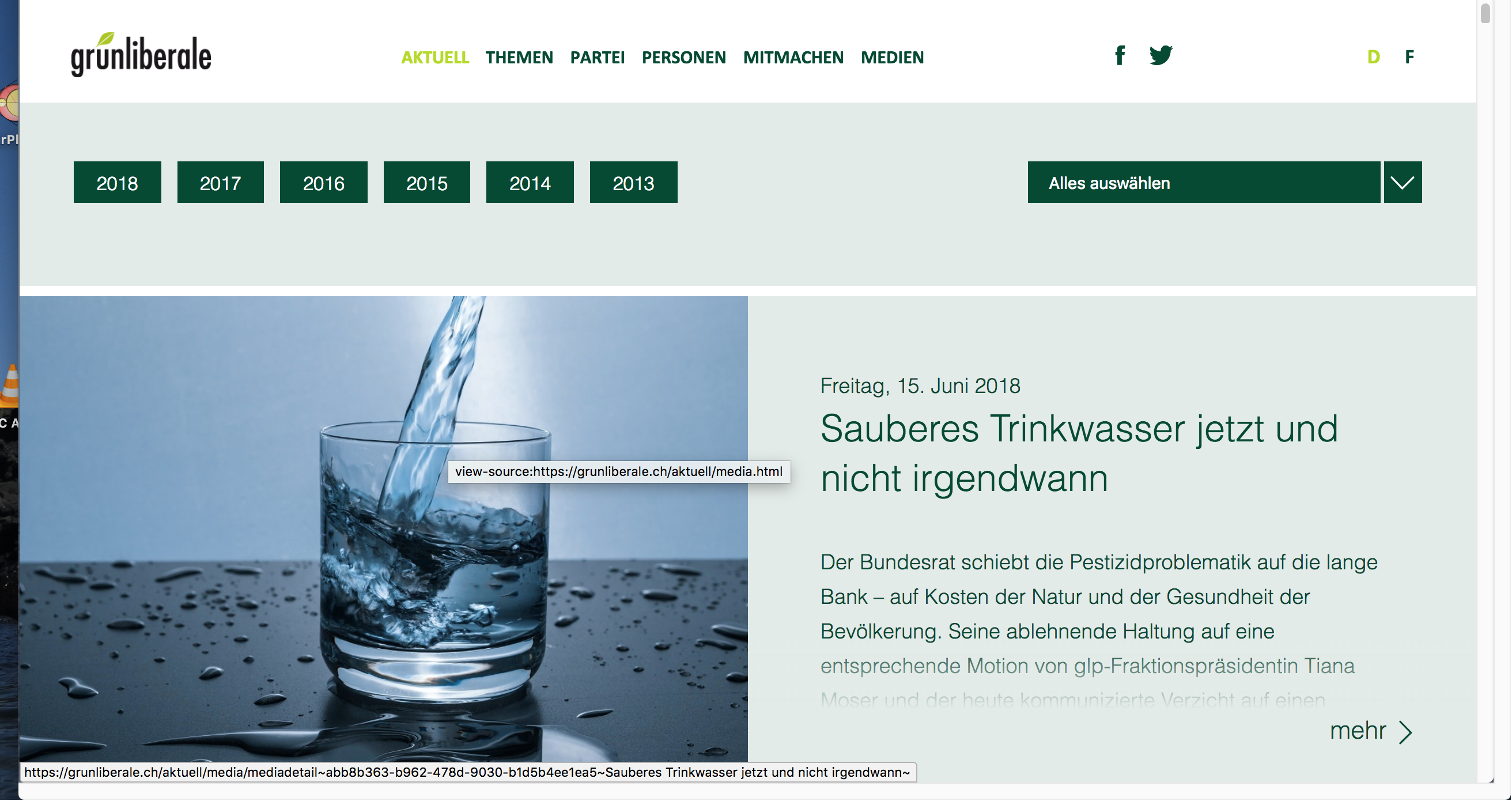
Figure 9.1: This is the normal page view
Then look at the structure and code of the webpage. For this you have to display the source code of the webpage by pressing ctrl+U on PC and cmd+alt+U on mac. You should see something like this:
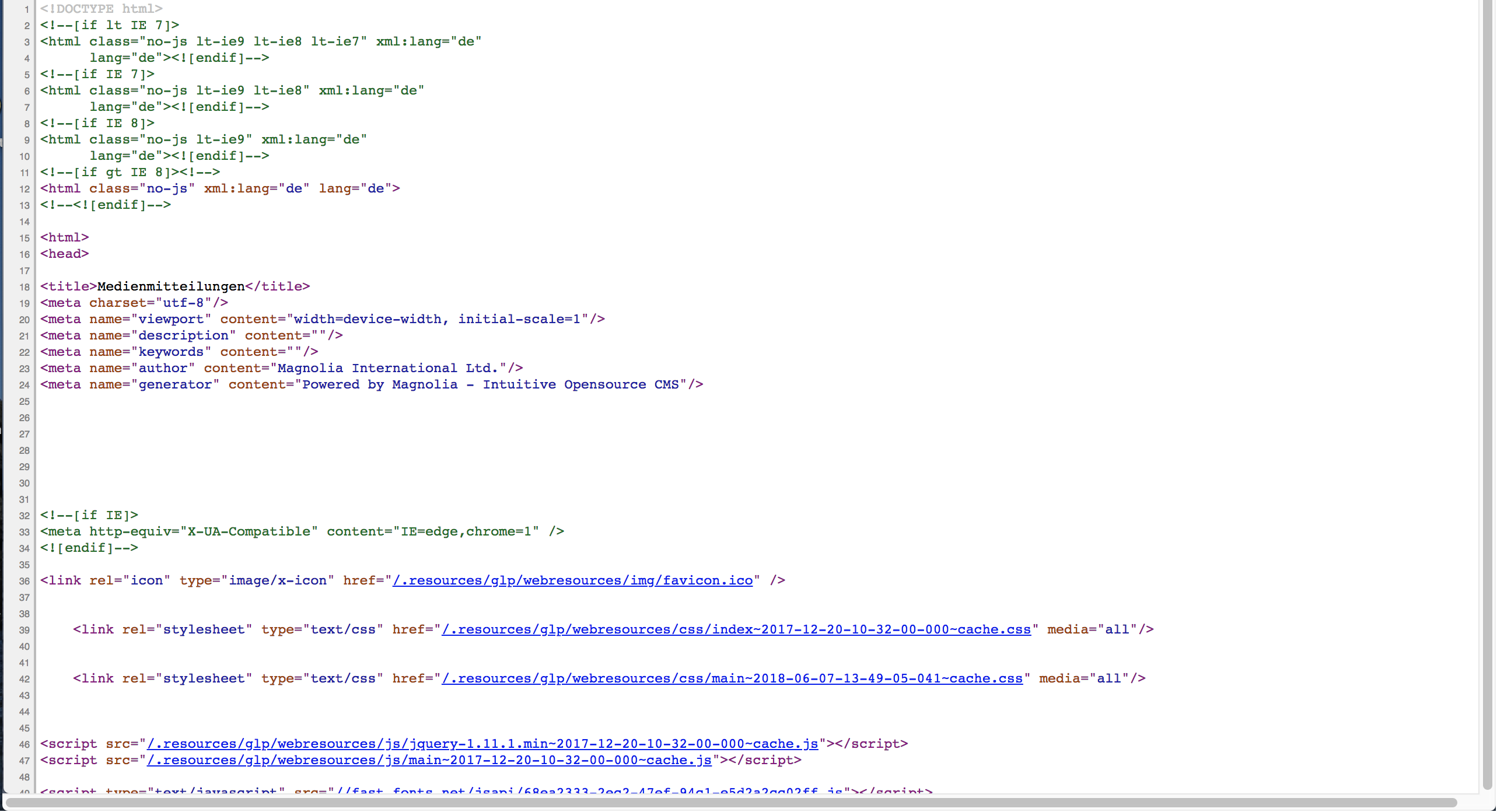
Figure 9.2: Here you see the sourcecode view of chrome
You can use the source code to search for the right paths to get the data down. We recommend using chrome as it has some nice plugins which make it easier to build a web scraper These plugins are the SelectorGadget and Scraper. Both can help you find the css and xpath’s of elements from a webpage. Keep the window open at all times during coding, as you will need it throughout most steps.
In this example we will gather all press releases from the GLP (Green liberal party of Switzerland). Hence, we search where on the webpages these press releases are located. By browsing through the page, we find that the links to all press releases are located in the subpage ‘aktuell’. Therefore, this is the URL we will start from with our web scraper. Now let’s start with our scraper.
9.3.2 Step 2)
Set the directory to the folder you will save the data in.
Save the URL in a variable and set the connection timeout to a high value. This makes sure that even if the webserver is very slow we will get no error message from R when the response from the webpage takes some time.
9.3.3 Step 3)
Now we want all links to the press releases. An easy way to get them is to simply read the whole site which contains all links to the press releases at first. Some pages will not show all press releases at once but show only 20. In this case you can just build a loop around this section to obtain all links from the whole list.
Then we have an object in our R environment which contains the whole source code of this page. Therefore, we need to filter for the links. Now go to your browser and try to distinguish the xpath of the links. If you do not find them, don’t worry, you need some practice to find them by hand. Let’s try out a nice base function from chrome which helps a lot when you are new to html. Right click on the first press release and then click on inspect element. This opens the ‘DevTools’ Elements panel. The panel displays the source code of the webpage and marks the element you clicked on.
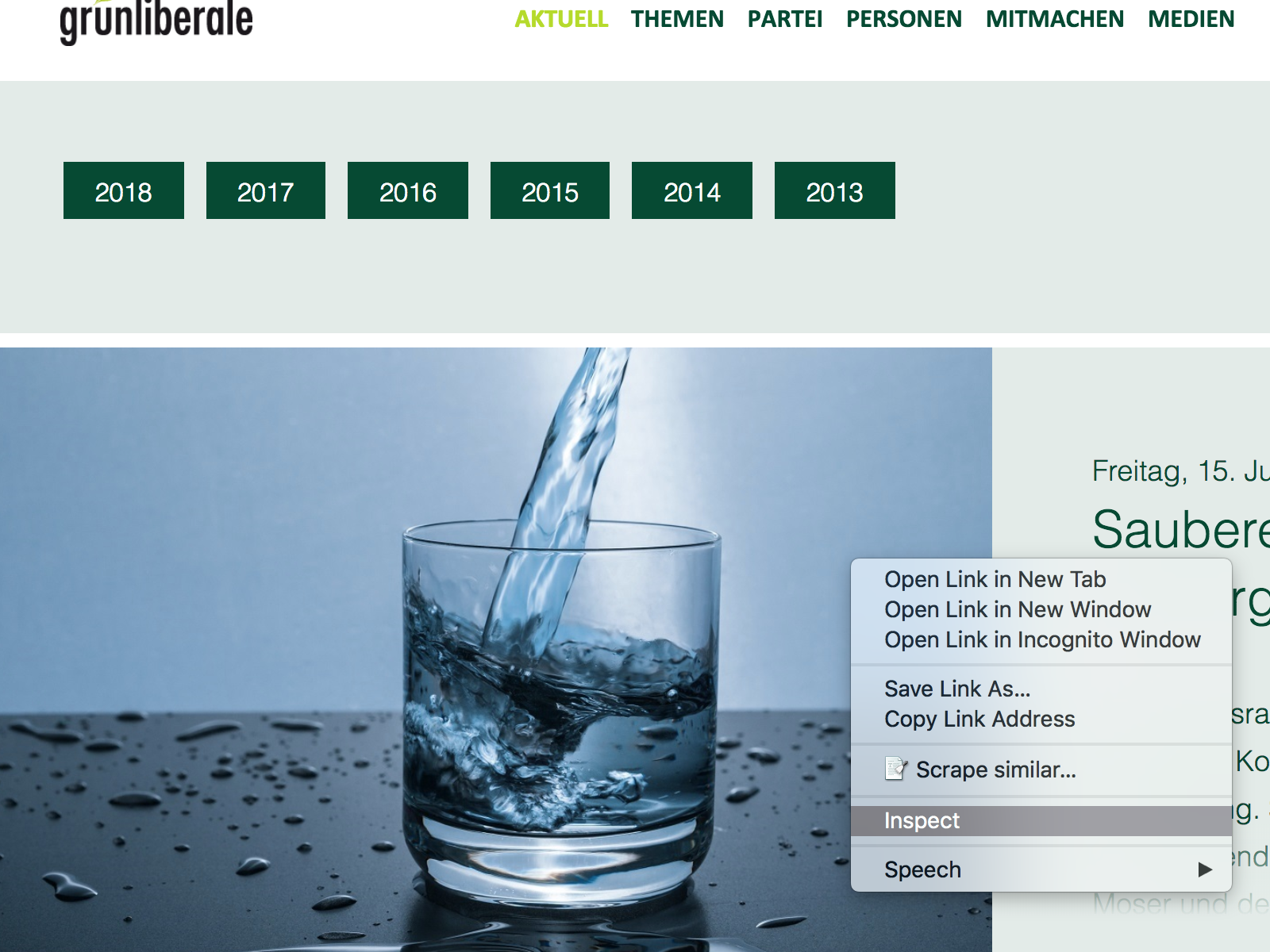
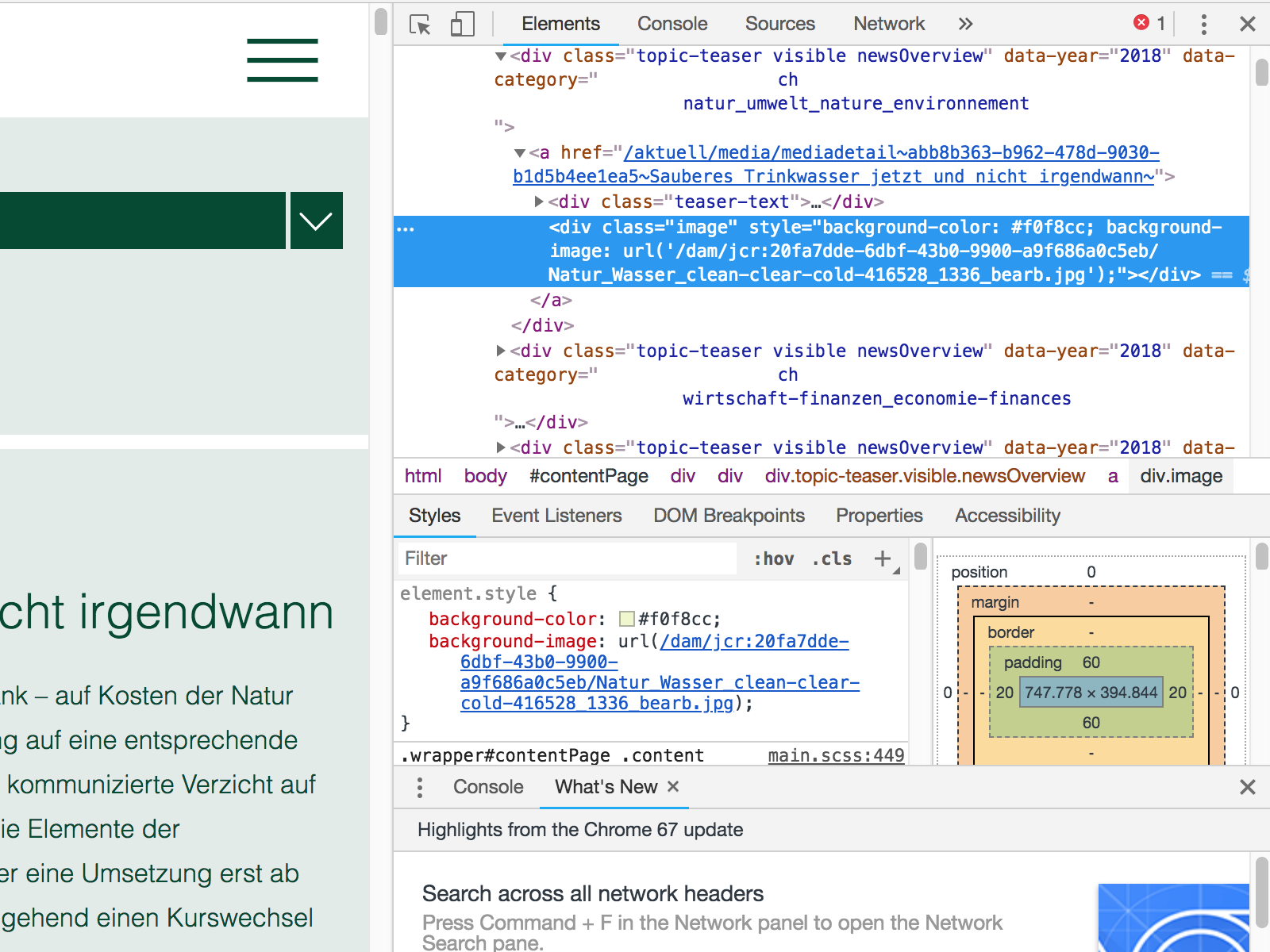
Figure 9.3: On the left is the menu and on the right you see the open development tool with the marked element
In this example it is either a teaser text or an image depending on whether you clicked on the teaser or the picture. Now when we look closer at the text in the dev tool right above the teaser text div we find the link to the press release. Now, to get the xpath to this link: The only thing you have to do is right click on this link and then select Copy on the menu. Then a new sub-menu will open where you select Copy xpath.
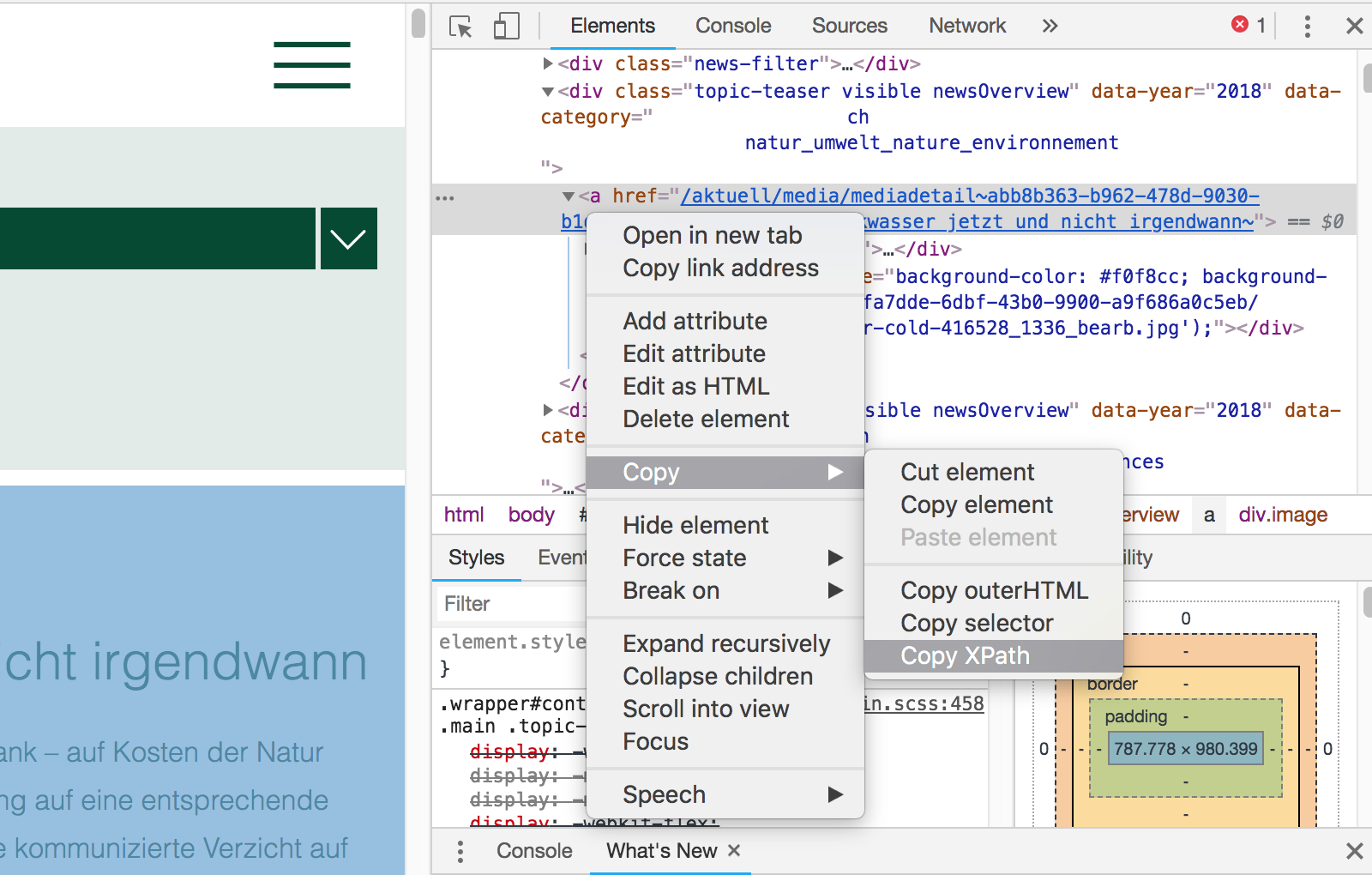
Figure 9.4: Here you see how to select the XPath element of your choise.
Now this is the path for this specific press release. It should look like this: //*[@id="contentPage"]/div/div[2]/div[3]/a when you paste it to your script. The only thing you have to know about html here is that it uses a tree like structure. Hence, we want to extract all objects residing on this exact node. So we write: //div/div/div[2]/div/a instead of what we copied before. This ensures that we not only extract the link from one particular press release but all press releases which are shown on the page. This is done as shown in the following line of code. We use a small pipeline which extracts the html node with the links from the whole page file we obtained when we read the html file of the page.
9.3.4 Step 4)
In the next step we extract the links from the html attributes. This returns a list with all the links. For easier handling we transform the list into a data frame and remove empty and undesired cells. Since we will use these links to access the press releases with RCurl again, we transform them to characters. For some pages it is necessary to select only the links leading to the press releases from the data frame, while there are many links in your list which lead to other pages of the webpage. This can be done by selecting links which contain a keyword unique for all links leading to the data you desire. This ensures no link is looked at later with unwanted information. Furthermore, it reduces the amount of exceptions you have to code for to zero in most cases.
9.3.5 Step 5)
Before we start the loop scraping the information from the internet we construct an if-else clause, which comes in handy if you want to scrape the page on a regular basis for new published press releases. For this case the statement builds a new data frame if it is the first time the script is started. This helps to save the most recent press release we scrape in the end. In the beginning the data frame contains an example which will avoid the break element. Later the statement loads exactly this data frame which always contains the date and title from the latest press release scraped. This is used to ensure during the scraping that we will not scrape information already scraped earlier when we execute the script on a regular basis.
GLP_Mitteilungenold <- NULL
if(file.exists("GLP_Mitteilungen_latest.csv"))
{
GLP_Mitteilungenold <- read_csv("GLP_Mitteilungen_latest.csv")
} else {
Datum <- c("1900-01-01", "1900-01-01")
Datum <- as.Date(Datum, "%Y-%m-%d")
Titel <- c("XYZ ABC ", "LMN UVW")
Akteur <- c("Grünliberale Partei Schweiz", "Grünliberale Partei Schweiz")
Kürzel <- c("GLP", "GLP")
Quelle <- c("Source", "Source")
Text <- c("Text", "Text")
data <- data.frame(Datum, Kürzel, Akteur, Titel, Text, Quelle)
fwrite(data, "GLP_Mitteilungen_latest.csv")
old <- 0
old <- as.data.frame(old)
fwrite(old, "GLP_Counter.csv")
}
#Last download data frame for checking if new ones are really new
limit <- as.character(GLP_Mitteilungenold[1,4])
#Counter for ID using last ID from previous task
old <- fread("GLP_Counter.csv")9.3.6 Step 6)
To get all press releases from the webpage a simple method is to use a for loop. The first step is to make a data frame which will contain information to the last press release written to the disk. Then we count the number of links we have in the data frame which we have to access with curl to copy.
The next line of code is important if your system uses another language then the one used by the webpage. If your language is different you will have to set your system to the same language, as it simplifies transforming dates written in characters to date variables (this code only works on Mac OS and Linux systems).
With all these things set up we can finally build the loop. The basic task of the loop is to iterate through all links downloading each press release and transforming this text into a json file with the title, text, actor name, alias, source and the publication date and write it to the disk.
Sections of the loop:
The first step in the loop is to read the html code from the page. Here we paste the link for the press release together
Then pause the system for two seconds. This step makes sure we put not too much load on the webhosts’ server. If you leave this away the loop would be as fast as your internet connection is, which would result in a very fast execution of the task. But this would also put the webpage under a lot of stress.
Now we start extracting the data we want to save beginning with the title of the press release. To do this we look at the source code of a press release and search for the xpath of the title. Here it is simply
//h1, which stands for heading one. Use a pipe to extract the text from this object only. The next few steps are postprocessing the text in a nice format for our json file. Normally we remove line breaks as well as spare whitespaces.After we got the title we try to find a publishing date on the page. Once we find it we inspect it once again. After we got it, we transform it by removing all characters except for the date itself. Finally, we can transform it into a date type variable, which is good practice for later analysis.
Then we do the same thing for the text. We once again the text is embedded in the html structure. In this example we find that the text is separated in two parts. The first part is the lead and the second part makes up the main text body. We use the same procedure as for the title for both text parts and then combine both parts in one single string. After that it is always useful to remove spare whitespaces within the text itself by using a
gsubcommand as well.The next step is to add variables containing the actor name, its alias and the source of the press release.
Now we check if the current press release isn’t the same from the last execution of the script. If the newest press release is identical to the last, the loop ends with a break, otherwise it continues.
If it is a new press release we combine all variables in a temporary data frame which is written as a json-file on the disk. The key here is to give each file a unique name. We solve this by assigning the date and an unique id to the file name. At the same time, we combine the date, actor name, alias and title to a second temporary data frame. This is used to write a new control file, which is done after the loop.
#Scraper downloading and storing each file as a json file tagged as
#Medienmitteilung | Datum | GLP
GLP_Mitteilungennew <- data.frame()
numrow <- c(1:nrow(Links))
Sys.setlocale("LC_TIME", "de_DE.UTF-8")
#Loop scraping new text with checkup
for (i in 1:nrow(Links)) {
tryCatch({
linkpart <- Links[i,1]
pg2 <- read_html(paste0("https://grunliberale.ch", linkpart), .opts = myOpts)
Sys.sleep(2)
Titel <- pg2 %>%
html_nodes(xpath = '//h1') %>% html_text()
Titel <- gsub("\r?\n|\r", " ", Titel[1])
Titel <- trimws(Titel, which = c("both"))
Datum <- pg2 %>%
html_nodes(xpath = paste0('//*[contains(concat( " ", @class, " " ),',
'concat( " ", "date", " " ))]') %>%
html_text()
Datum <- gsub("\r?\n|\r|\t", " ", Datum)
#Remove everything before the comma (removes day)
Datum <- gsub("^[^,]*," ,"", Datum)
Datum <- trimws(Datum, which = c("both"))
Datum <- gsub("^.*?\n", "", Datum)
Datum <- as.Date(Datum, "%d. %b %Y")
Text1 <- pg2 %>%
html_nodes(xpath = '//*[@class="lead"]') %>% html_text()
Text1 <- gsub("\r?\n|\r|\t", " ", Text1) #Removes \n 's
Text1 <- trimws(Text1, which = c("both"))
Text1 <- paste(Text1, sep=" ", collapse=" ")
Text1 <- trimws(Text1, which = c("both"))
Text2 <- pg2 %>%
html_nodes(xpath = '//*[@class="text"]') %>% html_text()
Text2 <- gsub("\r?\n|\r|\t", " ", Text2) #Removes \n 's
Text2 <- trimws(Text2, which = c("both"))
Text2 <- paste(Text2, sep=" ", collapse=" ")
Text2 <- trimws(Text2, which = c("both"))
Text <- paste(Text1, " ", Text2)
#Remove redundant white spaces
Text <- gsub("(?<=[\\s])\\s*|^\\s+|\\s+$", "", Text, perl=TRUE)
Akteur <- "Grünliberale Partei Schweiz"
Kürzel <- "GLP"
Quelle <- "https://grunliberale.ch/aktuell/media.html"
if(Titel == limit){
break
}
old <- old + 1
tmp <- data.frame(Datum, Kürzel, Akteur, Titel, Text, Quelle)
tmp2 <-data.frame(Datum, Kürzel, Akteur, Titel)
mytime <- Datum
myfile <- file.path(getwd(), paste0("GLP_Medienmitteilung_", mytime,
"_ID_", old, ".json"))
write_json(tmp, path = myfile)
GLP_Mitteilungennew<- rbind(GLP_Mitteilungennew, tmp2)
}, error=function(e){cat("ERROR: ", conditionMessage(e), i, "\n")})
}9.3.7 step 7)
The last thing we do in our script is checking if we scraped any new press releases at all. We do this by simply looking at the data frame containing all press releases written in the loop. If there is one or more it will save this file as the control file for the next execution by overwriting the old one. If the script has been executed the first time it overwrites our example control file generated before which will then be used for further executions to prevent the script from downloading already scraped press releases.