3 Data Collection procedures
We will show you how we gather the data, which also informs you about the data types we currently have available for research.
The presented scripts are examples which closely resemble the actually running scripts on our server. Given that we collect data for multiple users and have automatized data collection as far as possible, for the documentation of our processes certain elements are simplified. For more information on the live scripts and data collection processes please contact us directly (see Access page).
We mostly use R for data collection, but also Python and other programming languages. The database with the collected data runs on a cluster using Elasticsearch. Our cluster running Elasticsearch uses several machines for redundancy and scalability. For easy monitoring we rely on Kibana as user interface for our elastic cluster. Elasticsearch is a ‘non-relational’ database built for textual data which should be searchable. Additionally, elastic allows to post process data and analyse it directly within while saving the results in the database. Before we get into the different scripts used to collect the data, we need to talk about the infrastructure one needs to collect data in an automated manner from many different sources.
This is an important topic. It is relatively easy to collect data once for a project from a single source or even several sources after one has written the necessary programs collecting the data. The difficulty starts as soon as one’s goal is to collect data over a longer period of time or collect it from many different sources. Our goal was from the beginning on to not only collect data for one single analysis but to collect important data on the swiss political discourse not only on social media but also from official sources and newspapers over a long time. This meant we had to develop a framework with which it is possible to collect different data continuously. To achieve this, we reached out to our universities IT-Services (S3IT) to discuss what they could provide us with and what we need to do on our own. It turned out to be a good idea for us to let the S3IT handle the set-up of our research infrastructure. In detail they provide us with the hardware as well as the network including the firewall needed to handle all the different data. Additionally, they helped setting up a task scheduler for our data collection and processing scripts. Instead of using cron jobs on each node and allocating and balancing the tasks on these nodes by hand. S3IT provided us with a distribution system called ‘dcron’ (https://pypi.org/project/dcron/). This scheduler is central for our infrastructure. The main features of this program are the centralised scheduling of tasks over a web based graphical interface or a command line interface, the automated distribution of the tasks over different nodes for simple load balancing and the monitoring of the jobs allocated to the different nodes. Furthermore, they provided us with initial support to set up the database which we now run and update regularly. Most of the data collection and pre-processing (access data from sources via web scraping, APIs for Twitter as an example and Facebook over CorwdTangle and direct database access; process text data in machine readable format; add metadata such as date, source, actors; transfer everything automatically in our database) is done via dcron.
The infrastructure consists of three main components: data collection and pre-processing, data storage, and postprocessing and analysis. For data collection and pre-processing, we currently work primarily with textual data obtained from various sources using web scraping, the Twitter REST API, and direct database access. As soon as the data are downloaded, they are pre-processed into a machine-readable format and augmented with metadata such as source, date, and actors. After pre-processing, the data are stored temporarily in a JSON archive before being transferred into the second component of the infrastructure, the database. Our data are stored in a non-relational, searchable database built with Elasticsearch, using multiple nodes for redundancy and scalability. Data analysis routines are implemented in the third component of the infrastructure, which relies on multiple separate nodes. They sometimes include docker containers for reproducible supervised classifications as well as scripts for tasks such as named entity recognition, sentiment analysis, and topic modelling.
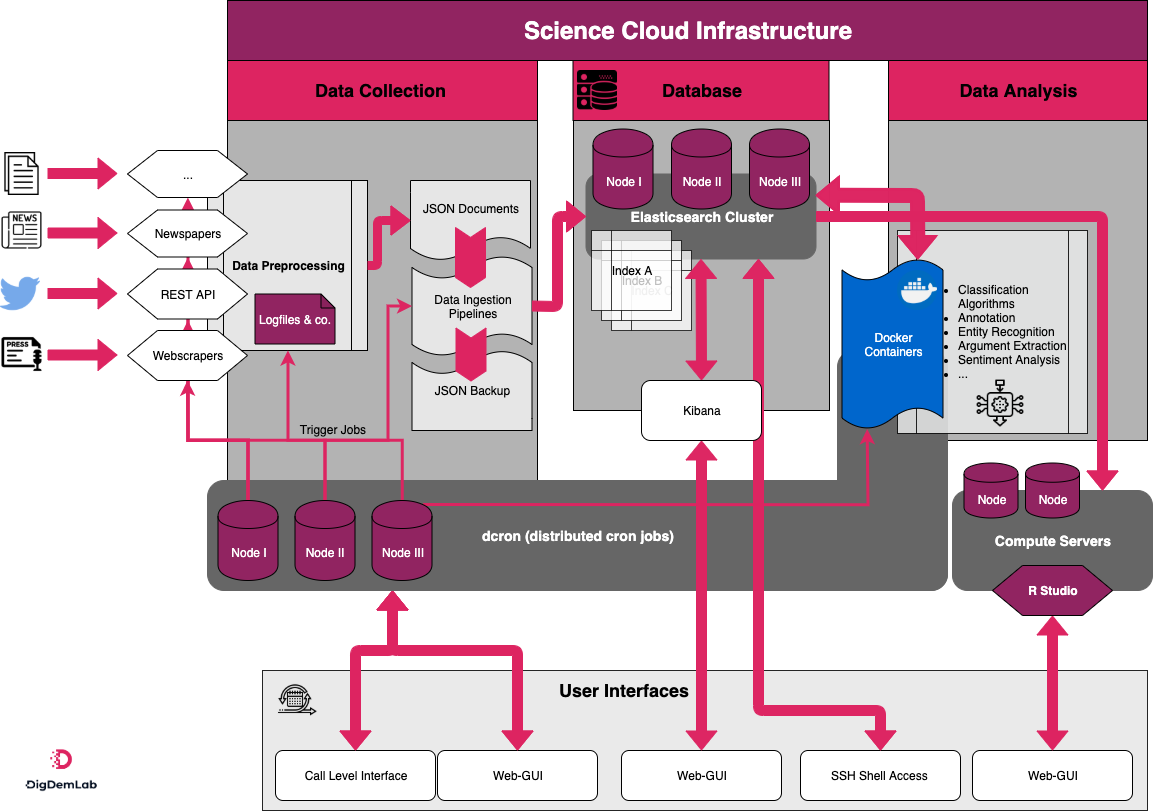
Figure 3.1: The DigdemLab infrastructure in detail
Hence the key characteristic of the infrastructure is the capacity to automatize and schedule all tasks, from data collection and pre-processing to analysis. We use dcron to distribute tasks both across time (for instance, to comply with API restrictions) and across nodes (to manage the computing load). The infrastructure is hosted on the computing and storage infrastructure of the University of Zurich (ScienceCloud), which ensures data encryption and protection. It can be accessed via GUIs such as the dcron website, Kibana, and R-Studio as well as via the command-line interfaces. Additionally, the infrastructure allows for easy and fast expandability. This ensures that we are fast to adapt our data collection to short events which require us to be fast in setting up new data ingestion services.
Hence, we are able to collect data from thousands of Twitter accounts. In detail we collect data from around 1500 Accounts at the moment. This includes official accounts from the swiss government, parties and of course the politicians themselves if they have an account. As of writing the collection entails over three million tweets from these users alone and over 10 million newspaper articles from the swissdox newspaper archive.